
本文章旨在比較 Jekyll 與 Medium 的排版能力,證明 Jekyll 較為優勝
傳送門:更新至 2018年11月14日 的 q-importance 分數,有興趣可自行複製研究
在街工的歲月裡歷經兩場立會新西選舉,2012 年與 2016 年街工分別派出梁耀忠和黃潤達出選,結果是 2012 年梁耀忠得票 43,799,2016年黃潤達得票 20,974,相差 22,825 票。2016年的內外部檢討,除了由前輩老掉牙地說地區工作不夠好,批評雷動失調,馮檢基空降亂入外,亦有提及黃潤達的知名度不足。然而,知名度的比較和提昇,卻一直因缺乏客觀的度量衡以供檢討,令團體內部隱約把追求知名度與激烈行動換曝光劃上等號,無助討論更製造分化。
有幸聽過思為策略羅棋駿的分享,了解到上述問題可靠分析新聞嘗試處理,因近期在網上找到了某一網媒過去近三年新聞檔案的 json,便嘗試著手開發知名度排行的方法 q-importance,以呈現新聞人物的相對知名度。
知名度的數學模型
為了釐定每天的相對知名度高低,知名度有有以下六項前設:
- 若沒有新的新聞,知名度會隨時間下降
- 人物報導越新近,知名度會相對其他人高
- 人物有更多報導,知名度亦會相對高
- 人物有更頻密的見報率,知名度會相對穩定
- 人物於報導中出現位置較早,會較於報導較後的人有較高知名度
- 人物會記住與自己出現在同一報導的其他人
基於上述假設,我們可以基於新聞數據建立一張圖(graph),首先把每一位人物當成一個頂點(vertex),若兩位人物同時出現在一篇報導中,我們以一條邊(edge)把代表兩位人物的點,從而構成一幅人物網絡。之後,再參考遺忘曲線為每條邊的距離賦值,越小的值代表兩位人物對對方的印象越深刻。透過這方法,可得出類似下圖:
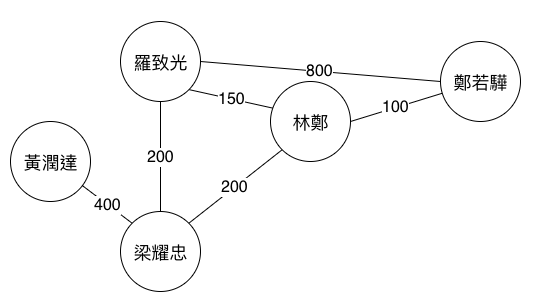 越小的值代表兩人對對方印象越深
越小的值代表兩人對對方印象越深
然後,我們可以計算每個頂點的緊密中心度(closeness centrality),每個緊密中心度的值,代表每個人物與其他所有人物的接近程度,接近程度越高,反映出人物的知名度亦越高。
Python 的知名度算法實現
以 python 求上圖的 closeness centrality 的話,代碼如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# -*- coding: UTF-8 -*-
# 載入 networkx library
import networkx as nx
# 創義一張圖到變數 D
D = nx.Graph()
# 把各條邊和距離/權重加到各人物的頂點上
D.add_edge('羅致光', '鄭若驊', weight=800)
D.add_edge('羅致光', '林鄭', weight=150)
D.add_edge('羅致光', '梁耀忠', weight=200)
D.add_edge('林鄭', '鄭若驊', weight=100)
D.add_edge('林鄭', '梁耀忠', weight=200)
D.add_edge('黃潤達', '梁耀忠', weight=400)
# 呼喚在 networkx 裡的 closeness_centrality 程序,並把結果存到變數 rank
rank = nx.closeness_centrality(D, distance='weight')
# 把結果放大以便閱讀,並逐行輸出
for k, v in rank.iteritems():
print k, v * 10000
結果輸出如下,大體符合普遍印像。
| 人物 | 中心度/知名度 | 排名 |
|---|---|---|
| 梁耀忠 | 36.36 | 2 |
| 羅致光 | 33.33 | 3 |
| 鄭若驊 | 29.63 | 4 |
| 林鄭 | 38.10 | 1 |
| 黃潤達 | 17.39 | 5 |
循此方向,不難理解,邊的距離是知名度高低的關鍵所在,q-importance 參考遺忘曲線所定的距離公式如下:
\[{f(x,g)} = 500 ( { 1 - e^{-{x \over S \cdot g}} } )\]這裡的 $x 是指新聞距離今天的天數,$g 是人物在文章裡相對位置的幾何平均數,S 是根據其他日子的新聞量釐定出來的穩定函數,詳見 github。
q-importance 的選舉分析應用
回溯文首提到的 2016 年選舉,在缺乏地區工作和知名度的度量衡,只靠著票站票數胡亂開展討論的情況下,街工內部的分析難免只流於空泛討論,也難有結論,但現在有了 q-importance,我們可試試回頭分析 2016 年最後一席的泛民內鬥,數字詳見此處。
下邊的結果是以 q-importance 分析由 HK01 自 2015 年 11 月 28 日至 2016 年 9 月 4 日的所有文章得出的資料,難免有所偏頗,歡迎讀者提供更多報章資料以作分析。
2016 年黃潤達選舉結果研判
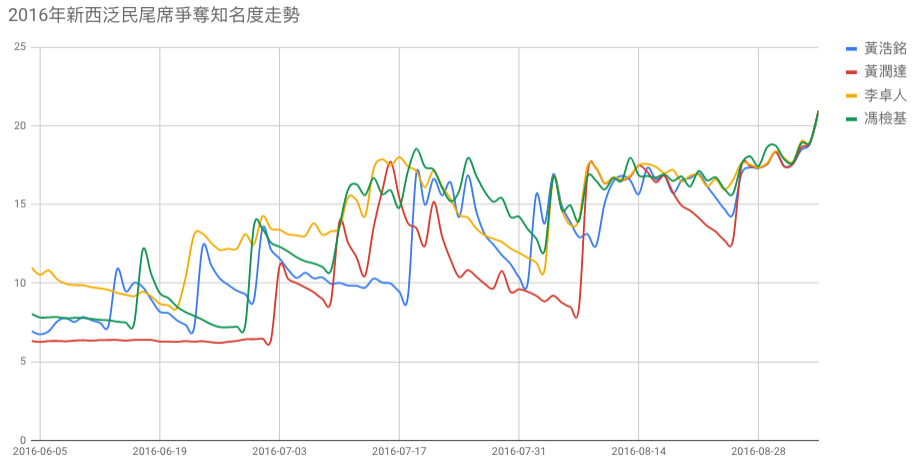 2016年黃潤達的知名度明顯低迷
2016年黃潤達的知名度明顯低迷
以 q-importance 回頭分析 2016 年選舉前三個月,黃潤達的知名度,可以看到黃潤達長期與其他泛民尾席的競爭者比下去,配合票站票數的逆序比例分析(下圖),黃潤達的票數明顯集中於個別選區(極強地區工作的結果),而其他選區均告慘敗,這與上邊提到的知名度低迷狀況吻合。
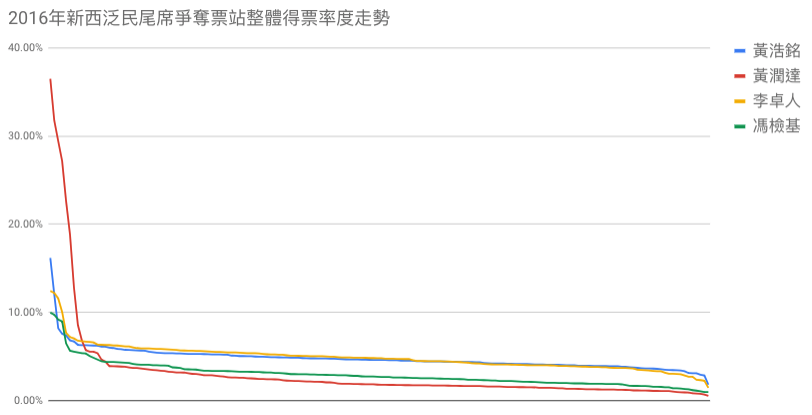 按各候選人得票率高低從左至右表達平均得票率
按各候選人得票率高低從左至右表達平均得票率
2016 年黃浩銘選舉結果研判
反觀黃浩銘,知名度實際上好不了黃潤達多少,然而,他的得票卻向李卓人靠攏,這邊的原因可靠結合陳偉業的知名度分析(兩人每天知名度的最大值)得到解釋,這反映陳偉業的「抬轎」效應而賦予的(見下圖)。
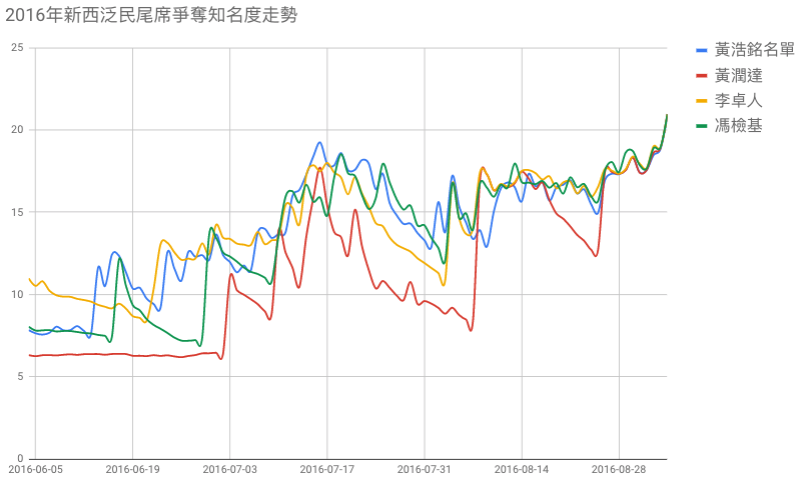 把陳偉業的知名度考慮進黃浩銘身上,知名度即提升一個層級
把陳偉業的知名度考慮進黃浩銘身上,知名度即提升一個層級
在這裡必需向每位願意抬轎的政壇前輩致敬。至於,仍繼續參選九西補選的馮檢基與李卓人,和2020 年仍想出選的梁耀忠⋯⋯
2016 年馮檢基選舉結果研判
雖然知名度也緊從李卓人與黃浩銘名單的走勢,但馮的得票明顯不及他們,但仍然在大部份票站的壓過黃潤達。這裡要給出解釋並不容易,但可能性包括,q-importance 給出的只是不分正反的知名度,我認為當時有關馮檢基的報導多較負面是非常大的關鍵,但實際上如何能更好反映知名度與得票的關係,實在要靠更好的數學模型去解釋了。
結論
q-importance 主要是建立一套適用於本地人物的知名度度量衡,它的建構就是依靠媒體的報導,以客觀的方式計算人物的知名度,這度量衡有助於分析人物的影響力。
而若同意這模型的合理性,要在社會上追逐知名度,方法除了搶曝光外,還要搶跟誰一起曝光,爭取的訴求當然是由林鄭來回應要比由羅致光來得有用。同理,團體內外要衡量誰能成為代表出選,除了論資排輩,比拼組織起來的群眾力量外,也可比較知名度以估量大眾的認受性高低。
發展上,q-importance 理論上還可以把議題擬人化,當成人物去換算議題的知名度,以助相關人士選擇議題跟進,又或檢討擴廣相關議題的行動成效。
P.S. 回想轉頭,這幾年來馮檢基沉迷的,到底是知名度還是支持度﹖實在難以捉摸🤷
註:九西11月25日補選,參選人包括伍迪希、曾麗文、李卓人、馮檢基、陳凱欣